Ist es einfach, eine R Markdown Datei als Quarto Datei zu ersetzen? Man sagt: ja. Und ich habe es ausprobiert.
Ich habe ein altes, kleines Statistik-Projekt aus dem zweiten Semester genutzt und den R Markdown Code in die Quarto Datei hineinkopiert. Das Ergebnis war sehr gut! Nur zwei Unterschiede sind dabei aufgefallen:
die zentrierte Formatierung der mathematischen Formeln im Abschnitt Hypothesen wurden nicht korrekt umgesetzt. Grund: gewisse Markdown-Formatierungsanweisungen funktionieren offenbar leicht anders, weil wir das ursüngliche Markdown Dokument als PDF-Output optimiert hatten.
fett dargestellter Markdown-Text wurde nicht fett ausgegeben: Grund: das verwendete Quarto HTML Theme (hier: lux) resp. dessen Schriftart stellt keinen fett geschriebenen Text dar. Das hat mich zunächst verwirrt, aber ist überhaupt kein Problem.
Fazit
Der Aufwand, um R Markdown in Quarto zu überführen, liegt nur bei sehr wenigen Minuten. Cool!
Ein Unterschied zwischen R Markdown und Quarto sind die nicht vorhandenen Chunk-Optionen bei Quarto. Diese fande ich noch praktisch, aber gut, nun muss ich sie mir endlich mal merken.
Zwei Tage nach diesem Beitrag habe ich herausgefunden, dass R Markdown automatisch direkt in die Quarto Website eingebunden wird. Dadurch entfällt das Umwandeln komplett. Bei den R Markdown Dateien muss möglicherweise nur die Meta-Daten anpassen.
Statistik Projekt (BZG1185ab)
Aufgabe 6: Männer essen Fleisch öfter als Frauen.
Von Claudio Comazzi, Omer Abdallah und Christian Franke (Klasse X1r)
Erstellt am 5. Mai 2022
Datengrundlage
Umfrage
Die Aufgabenstellung “Männer essen Fleisch öfter als Frauen” haben wir präzisiert, um die Datenqualität zu erhöhen.
Frage: “An wie vielen Tagen pro Woche essen Sie Fleisch?”
Umfrage in Bern Bümpliz vor einem Coop am 23.02.2022.
Umfrage in Bern Länggasse vor einer Migros am 26.02.2022.
Ganzzahlige Antworten zwischen 0 bis 7 waren möglich.
Es wurden das Geschlecht (m/w) sowie die Altersgruppe erfasst.
Es wurden insgesamt 75 Datenpunkte gesammelt.
Aufgrund der Umfrageorte und Umfragezeiten repräsentieren die Daten nur zum Teil die gesamte Bevölkerung (Details siehe im Ausblick).
Zusammenfassung der Datensätze in einer gemeinsamen csv-Datei und Analyse in R (Markdown).
data <-read.csv("input_data_fleisch.csv", sep =";")summary(data)
AnzTageFleisch Geschlecht Altersgruppe
Min. :0.00 Length:75 Length:75
1st Qu.:1.00 Class :character Class :character
Median :3.00 Mode :character Mode :character
Mean :2.84
3rd Qu.:4.00
Max. :7.00
Für Männer (n=43) liegt der Mittelwert bei 3.67 und die Standardabweichung bei 1.95.
Für Frauen (n=32) liegt der Mittelwert bei 1.72 und die Standardabweichung bei 1.82.
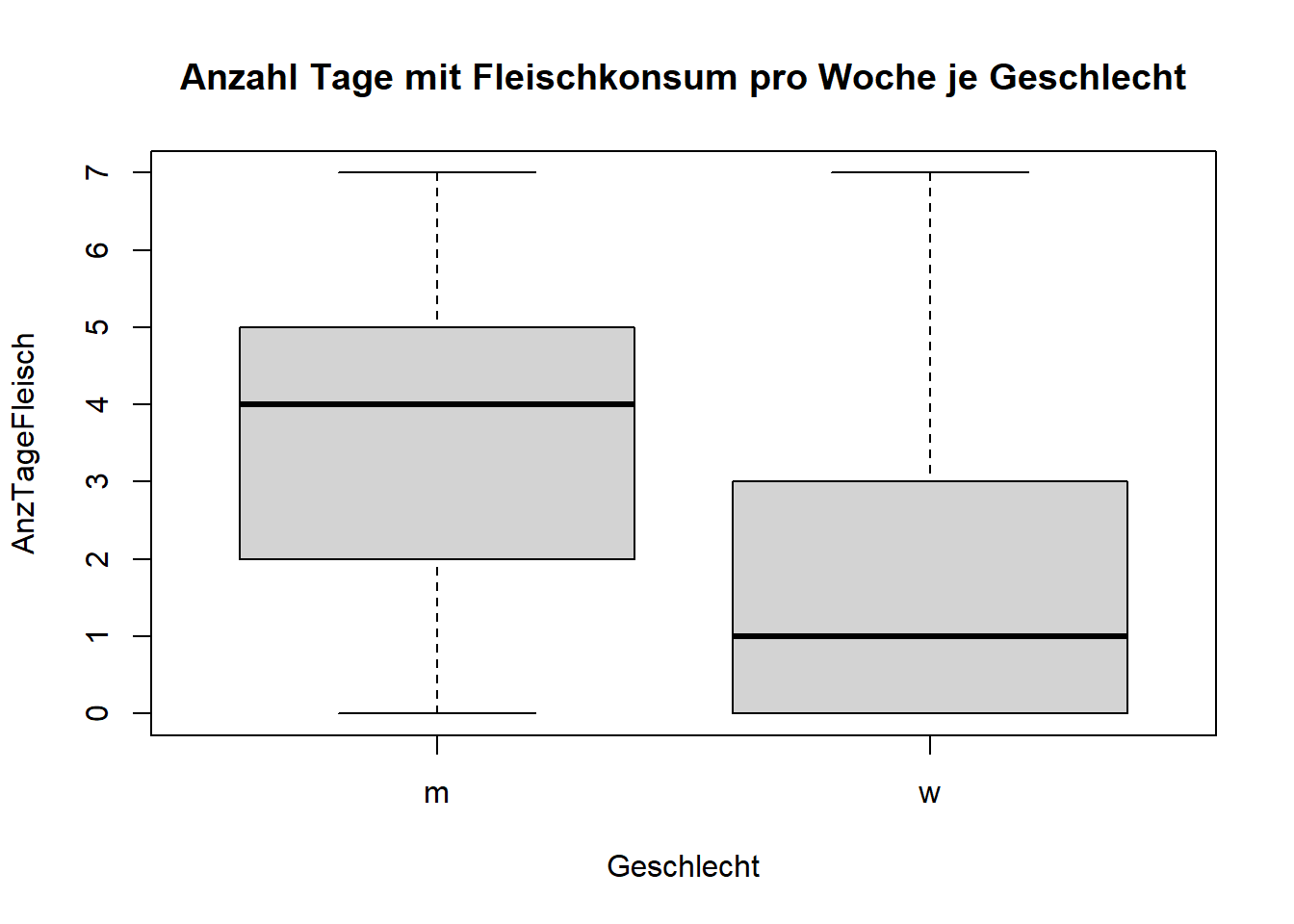
boxplot(AnzTageFleisch ~ Geschlecht, data = data , main="Anzahl Tage mit Fleischkonsum pro Woche je Geschlecht")
Die Verteilung der Frauen ist eher tiefer im Vergleich zu den Männern. Dies ist ein Hinweis, dass Männer öfters Fleisch essen, aber noch kein “Beweis”. Es müssen zunächst statistische Tests durchgeführt werden.
Hypothesen und Methoden
Hypothesen
Als Mittelwert verstehen wir hier das arithmetische Mittel aus der “Anzahl Tage mit Fleischkonsum pro Woche” (AnzTageFleisch). Die Nullhypothese lautet: der Mittelwert der Männer ist gleich gross wie der Mittelwert der Frauen. Als alternative Hypothese können wir schreiben: der Mittelwert der Männer ist grösser als der Mittelwert Frauen. Formal:
\(H_{0}: \mu_{m} = \mu_{w}\)
\(H_{1}: \mu_{m} > \mu_{w}\)
Methoden
Bei den Stichproben für Männer und Frauen handelt es sich um ungepaarte Stichproben, da die beiden Gruppen unabhängig voneinander sind. Weil deutlich mehr als 30 Datenpunkte vorliegen, könnten wir einen z-Test durchführen. Allerdings kennen wir die nicht die exakten Varianzen, sodass wir den t-Test verwenden. Da sich die Standardabweichungen von Frauen und Männer in unserer Umfrage nicht zu sehr unterscheiden, dürfen wir annehmen, dass die unbekannten Varianzen etwa gleich gross sind. Der t-Test ist eine sehr gute Approximation. Da n>30, müssen wir nicht die Voraussetzung auf Normalverteilung prüfen. Das Signifikanzniveau unseres t-Tests beträgt 5%.
Welch Two Sample t-test
data: m and w
t = 4.4681, df = 69.281, p-value = 1.499e-05
alternative hypothesis: true difference in means is greater than 0
95 percent confidence interval:
1.225962 Inf
sample estimates:
mean of x mean of y
3.674419 1.718750
Die Teststatistik ist mit 4.47 sehr gross. Der p-Wert liegt deutlich unter dem Signifikanzniveau von 5% und sogar deutlich unter 1%. Die Nullhypothese kann mit diesem kleinen p-Wert verworfen werden. Die alternative Hypothese wird nicht verworfen. Der Mittelwert der Männer scheint somit signifikant grösser zu sein als der Mittelwert der Frauen, d.h. Männer essen offenbar häufiger Fleisch als Frauen.
t-Test ohne Vegetarier (Ausreisser nach unten)
Problematisch ist möglicherweise die rechtsschiefe Verteilung bei den Frauen. In der Umfrage hatten 11 Frauen angegeben, dass sie vegetarisch sind und somit an 0 Tagen je Woche Fleisch essen (im Vergleich zu nur 4 vegetarischen Männern). Diese Frauen könnten einen grossen Einfluss auf das Ergebnis haben (ca. ein Drittel der weiblichen Beobachtungspunkte). Deshalb haben wir zusätzlich die Vegetarier aus dem Datensatz ausgeschlossen und den t-Test wiederholt.
Welch Two Sample t-test
data: m0 and w0
t = 3.2561, df = 40.943, p-value = 0.001136
alternative hypothesis: true difference in means is greater than 0
95 percent confidence interval:
0.6919657 Inf
sample estimates:
mean of x mean of y
4.051282 2.619048
Es fliessen nur noch 21 Frauen und 39 Männer in den Test ohne Ausreisser ein. Dies ist gross genug, um die gleiche Test-Methode durchzuführen. Die Mittelwerte sind erwartungsgemäss höher, aber der p-Wert liegt mit 0.1% noch immer deutlich unter unserem Signifikanznieau. Auch hier wird die Nullhypothese verworfen. Falls wir “alle Ausreisser” (AnzTageFleisch=7) entfernen, wäre der p-Wert weiterhin unter 1%.
Fazit und Ausblick
Man könnte in Zukunft z.B. das Alter oder weitere sozio-demographische Faktoren berücksichtigen. Dies hätte eine andere Fragestellung resp. ein anderes Studiendesign zur Folge. Jedes zusätzlich erfasste Merkmal steigert zudem den Aufwand bei den Umfragen. Man benötigt pro Altersgruppe genügend Daten und müsste mehr Zeit in die Datenerfassung investieren. In unserer Umfrage sind beispielsweise über die Hälfte der befragten Personen im Alter zwischen 30 und 39 Jahren gewesen. Dies repräsentiert die Schweizer Bevölkerung nur mässig.
Auf unsere Fragestellung, ob Männer häufiger Fleisch essen als Frauen, hat diese Besonderheit nur einen kleinen Einfluss. Insgesamt scheint es so zu sein, dass Männer häufiger Fleisch essen als Frauen.